There are few ready made YouTube video download library present in python already. “youtube-dl” is one of them which is very convenient to use. It also has command line interface (CLI) to download video from YouTube hence you do not need to use python code to download video. This article is for some more details. In the subsequent sections as we make progress, we will know the details of the source code of the YouTube video page. We will scrape the most important and required content of the YouTube video page.
Technology [Read library] used to do this operations:
- Python – We are going to scrape the page using python code.
- BeautifulSoup – This is the most popular static HTML web page scraper in python.
- requests – Library to make HTTP request to get page from YouTube site.
- json – Library to handle JSON data.
Prerequisite
Before starting the scraping process, make sure about few things:
1. Knowledge in python is required.
2. Knowledge in BeautifulSoup is a plus.
3. Jupyter Notebook might be helpful to play around. But this is not compulsory, you can use any editor or IDE as per your choice.
4. Understanding JSON format will be helpful.
5. A YouTube URL that you want to scrape.
WARNING !! Please note that this tutorial is only for educational purpose only. Use it responsibly and ethically.
Let’s Start….
1. The source
In this post I am using one my own video to scrape. The link is https://www.youtube.com/watch?v=ZYxLt1-waik
Once you open the link, right click on the blank area of the page anywhere and click on the “View page source” option. A new tab will open with source code of the page. You can go through the code manually but it is very tedious job to do. Hence we have the library BeautifulSoup to parse the HTML code to break into meaningful and smaller section. So let’s jump into the python section now.
2. Loading required libraries
from bs4 import BeautifulSoup
import requests
import json
requests and json library comes with python3 install already. You may have to install the BeautifulSoup if not there.
pip3 install beautifulsoup4
3. The URL and get the page content
youtube_url = "https://www.youtube.com/watch?v=ZYxLt1-waik"
response = requests.request("GET", youtube_url)
Assigning the URL into a variable and getting the response using request method(GET).
4. Get into the Soup
soup = BeautifulSoup(response.text, "html.parser")
body = soup.find_all("body")[0]
scripts = body.find_all("script")
The first line is parsing the response text using html.parser and store the result in the soup variable. If you check the soup variable it is simple formatted HTML code itself visually but it is actually a soup object where we can do multiple operation like I did in next two lines.
In the next line, I took the “body” tag from the response text. In all website, normally there are one body tag present. YouTube is no exception. We are finding all “body” tags and taking the first one only. Remember, find_all method returns a list.
In the last line, we are again taking all the “script” tags into list variable scripts.
YouTube streaming video information is stored in a variable named “ytInitialPlayerResponse”. All the video URLs and metadata is stored in this variable in JSON format.

The above variable is present in the very first <script> tag inside the <body> tag. Hence we will process first entry in scripts list.
5. Get the JSON data that contains all video information including video URLs
result = json.loads(scripts[0].string[30:-1])
We are passing sub string of the script content. I checked that the first script is only the above variable assignment is there. So scripts[0].string is only below text is there:
var ytInitialPlayerResponse = {json data.....};
Hence we are taking the sub-string from position 30 to 2nd last element from the above string to load the json data into the “result” variable. (scripts[0].string[30:-1]). Please note that we have two methods under json library load and loads (with a “s”). load method take the json data from a file and loads take the same from a string. Just a note.
6. Analyzing result
Let’s take a look on the json data. What are the keys are present in the data:
result.keys()

We have many keys in the result dict. Our required keys are “streamingData” and “videoDetails”.
result['streamingData'].keys()
result['streamingData']['formats']
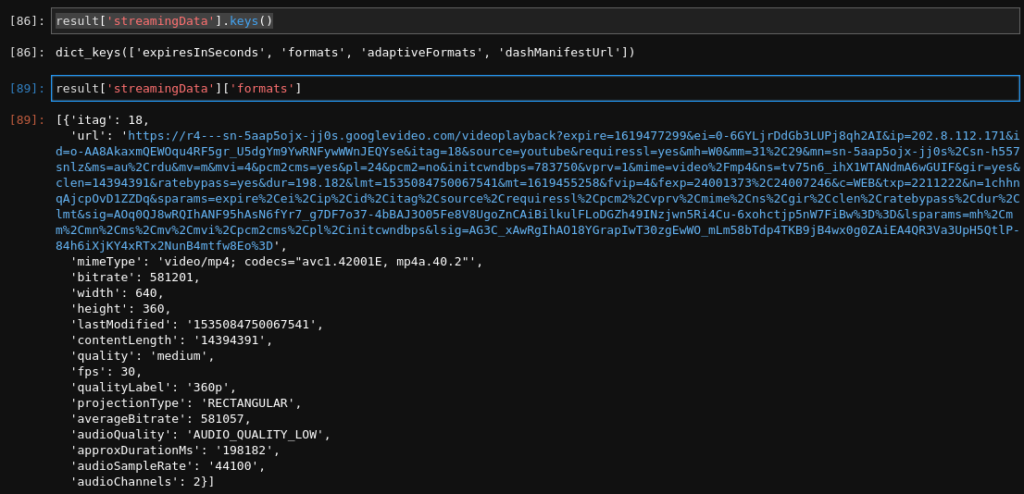
To get the other formats we can check the “adaptiveFormats” keys like audio only or higher quality videos.
result['streamingData']['adaptiveFormats']
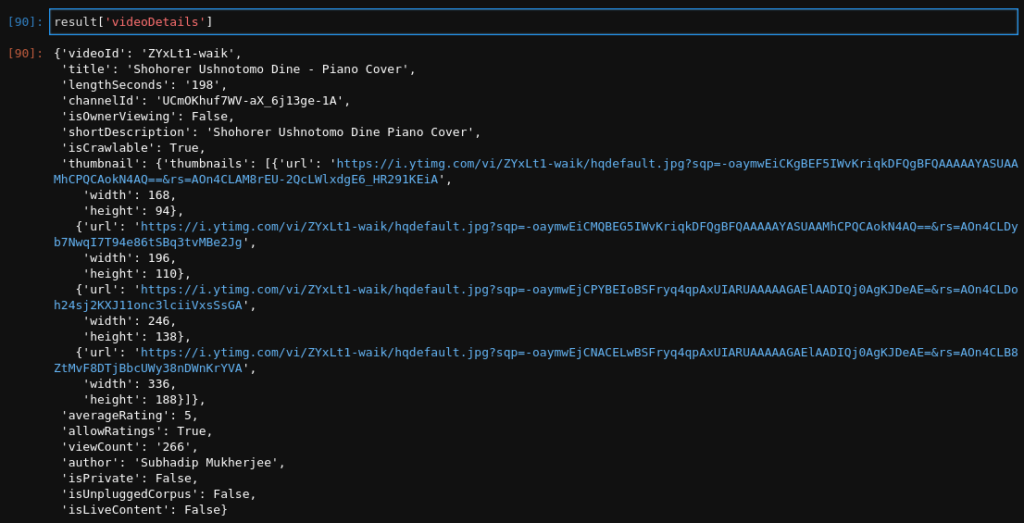
We can have the videoDetails as well:
result['videoDetails']
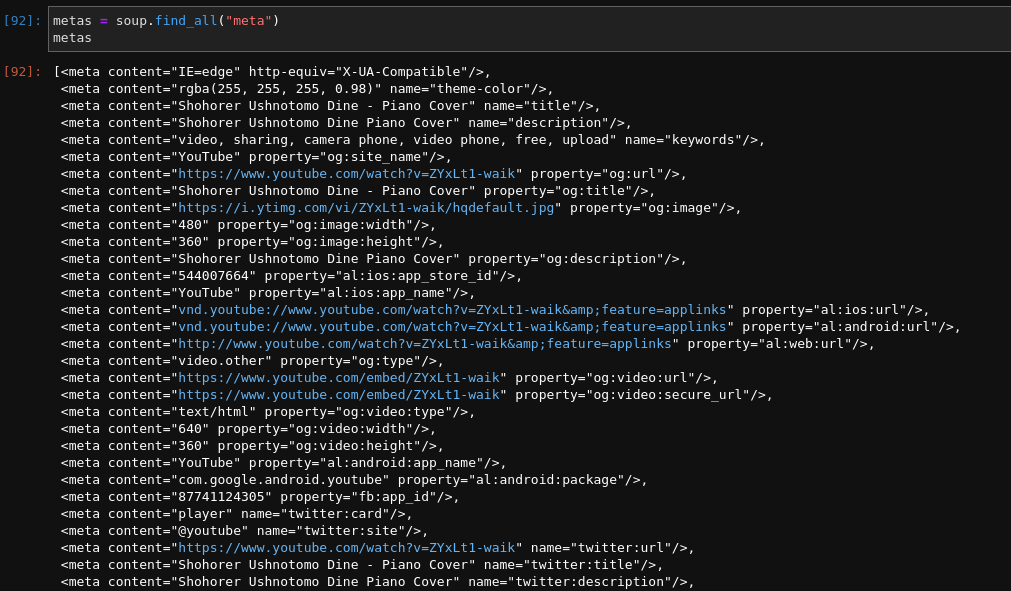
7. Meta information
We can get all the meta information that present in the YouTube source page.
metas = soup.find_all("meta")
metas
8. Everything together
from bs4 import BeautifulSoup
import requests
import json
youtube_url = "https://www.youtube.com/watch?v=ZYxLt1-waik"
response = requests.request("GET", youtube_url)
soup = BeautifulSoup(response.text, "html.parser")
body = soup.find_all("body")[0]
scripts = body.find_all("script")
result = json.loads(scripts[0].string[30:-1])
print(result['streamingData']['formats'][0]['itag'])
print(result['streamingData']['formats'][0]['url'])
print(result['streamingData']['formats'][0]['width'])
print(result['streamingData']['formats'][0]['height'])
Conclusions
So using above code base you can get the URLs of the videos and the metadata about the videos. Use these codes responsibly and ethically. Do not use if you are not allowed to do so. Also you can play around with the code to get other information as well.
Happy Coding !!!!