3. SQL vs AWK
Select only specific column(s) –
SELECT EMPNO, ENAME, SAL FROM EMP;
$ awk -F, 'BEGIN{OFS="\t";}{print $1,$2,$6}' EMP.csv
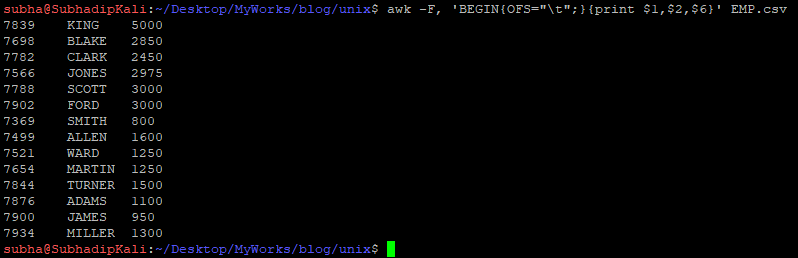
$1, $2 .. these are the columns in AWK. $0 is the entire line. Don’t worry about the OFS(Output Field Separator), you can ignore OFS. I put to get visual satisfaction only. If required you can put any other character like comma(,) or pipe(|). Default is space.
Filter Records, apply WHERE clause –
SELECT * FROM EMP
WHERE SAL >= 3000;
$ awk -F, '{if($6>=3000)print;}' EMP.csv

COUNT(), AVG(), SUM() –
SELECT COUNT(*) FROM EMP;
SELECT AVG(SAL) FROM EMP;
SELECT SUM(SAL) FROM EMP;
$ awk -F, 'END{print NR}' EMP.csv #count
$ awk -F, '{sum+=$6;}END{print sum/NR}' EMP.csv #average
$ awk -F, '{sum+=$6;}END{print sum}' EMP.csv

NR stands for number of rows. END is required because otherwise it will print all row numbers. But we need the maximum one(or last one) only.
sum+=$6 will iteratively add all the salary from the file. At last either you can use sum or sum/NR at the END.
MAX(), MIN() –
SELECT MAX(SAL) FROM EMP;
SELECT MIN(SAL) FROM EMP;
$ awk -F, '{if($6>max)max=$6;}END{print max;}' EMP.csv #max
$ awk -F, 'NR==1 {min=$6} NR>1 && $6<min {min=$6} END{print min}' EMP.csv #min

MAX is easy. keeping the salary value in max variable and checking if salary is greater than previous value. If yes, update max. At END print max.
MIN – keep the first salary in min variable. Check for row number greater than 1 (NR>1) and see if it has salary value lower than min, if yes, update min. At the END, print min.
GROUP BY –
SELECT DEPTNO FROM EMP GROUP BY DEPTNO; --Distinct DEPTNO
$ awk -F, '{a[$8]="";}END{for(i in a){print i;}}' EMP.csv
a[] is the associative array with DEPTNO as index. Index in a array is unique hence this is small but effective hack of using associative array. There are multiple other ways as well do achieve this. One example is like below:
$ awk -F, '{print $8}' EMP.csv | sort | uniq
or
$ cut -d"," -f8 EMP.csv | sort | uniq
uniq is command to get single occurence of input in case of duplicate. sort is necessary because uniq only removes duplicate from subsequent repetition.
CAUTION !! DO NOT use cat command to open file then pipe into awk or another command. IT’S VERY BAD USE OF CAT.
$ cat EMP.csv | awk…..
COUNT/SUM/AVG with GROUP BY –
What is the total salary is being paid each department?
What is the count of employee per department?
What is the average salary per department?
SELECT DEPTNO, SUM(SAL) FROM EMP GROUP BY DEPTNO;
SELECT DEPTNO, COUNT(*) FROM EMP GROUP BY DEPTNO;
SELECT DEPTNO, AVG(SAL) FROM EMP GROUP BY DEPTNO;
$ awk -F, '{a[$8]+=$6;}END{for(i in a){print i,a[i];}}' EMP.csv #sum
$ awk -F, '{a[$8]++;}END{for(i in a){print i,a[i];}}' EMP.csv #count
$ awk -F, '{a[$8]+=$6;b[$8]++;}END{for(i in a){print i,a[i]/b[i];}}' EMP.csv #average

GROUP BY is being achieved by associative array. Here we are assigning different values in that array to get sum/count. Adding SAL in that array to get the SUM of SAL. Counting up (++) to get Count. Finally for average we are using both to get average.
If you are unclear with this, leave a comment I will explain more.
Derived Column –
You can derive new column based on the current column. You have to know how many columns are already there in current file. NF (Number of fields will be our weapon here.
$ awk -F, '{print NF}' EMP.csv | sort | uniq
Above code will give you number of fields in each record. sort/uniq to get distinct value only. By this command you can verify if in your file, each record has same number of fields or not.
Once you have the NF, use NF+1 to new derived column. Our case, NF=8, So new column will be $9. Below command will give you annual salary of a employee in 9th column:
$ awk -F, '{$9=$6*12;print;}' EMP.csv | column -nt
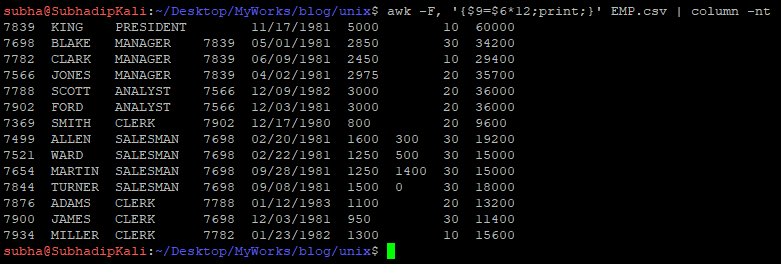
New column is SAL*12 (Annual Salary). column command is just to format output.
CASE-WHEN –
If salary of an employee is greater than or equal to 2500, then he is GRADE-A employee. SAL >=1500 to 2499 is GRADE-B and SAL<1500 is GRADE-C employee:
SELECT EMP.*,
CASE WHEN SAL >= 2500 THEN 'GRADE-A'
WHEN SAL >= 1500 AND SAL <2500 THEN 'GRADE-B'
WHEN SAL < 1500 THEN 'GRADE-C'
END AS EMP_GRADE
FROM EMP;
$ awk -F, '$6>=2500 {$9="GRADE-A"} $6>=1500 && $6<2500 {$9="GRADE-B"} $6<1500 {$9="GRADE-C"} {print}' EMP.csv | column -nt
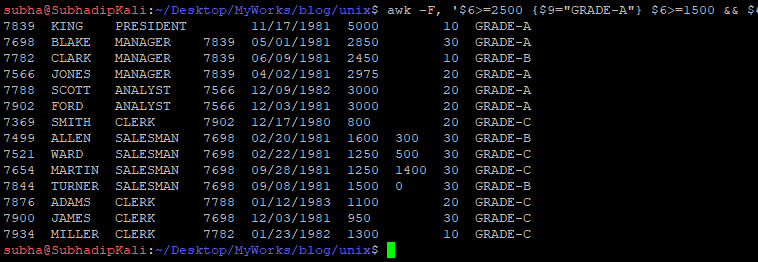
ROW_NUMBER()/Analytical Functions –
Calculate department wise Employee serial Number:
SELECT EMPNO,ENAME,DEPTNO,
ROW_NUMBER() OVER(PARTITION BY DEPTNO ORDER BY '') AS EMP_SERIAL
FROM EMP;
$ awk -F, '{pb[$8]++;print $1,$2,$8,pb[$8];}' EMP.csv | column -nt
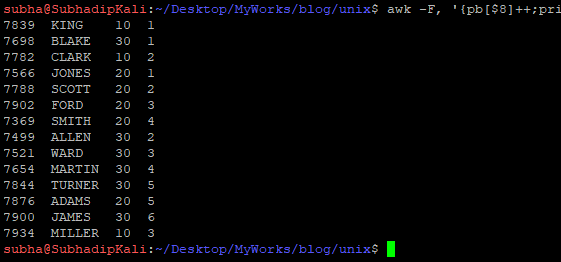
Here partition by column is $8. Increasing the value of pb[$8] array is same as ROW_NUMBER. If you don’t have any partition by column then simply refer NR variable.
So you have learned basic SQL to AWK conversion. You can mix other command with awk to achieve your result as per the requirement. AWK is really fast if you have large file to precess.
Now let’s jump into some complex operation like JOINS – inner/left. Read on Page 4..
Great content. This help alot. Thank you so much.
No problem. Thanks to you too for going through the content.
What a great content 🙂
Thanks
Thanks Jessica !! It means a lot. 🙂
The problem is that awk is NOT a CSV parser.
I.e. with the , separator, if we have a field value of “SURNAME,NAME” in this case the AWK threats it as two different fields.
Use goawk instead.
Yes. Good point. If the delimiter is part of the column value itself, then awk will fail to operate. We always encourage to use character like pipe or something else as delimiter which doesn’t present in the data. GoAWK is good solution for this. But yet to available as part of distributions.