Introduction
Data Warehouse and Business Intelligence involves all about data handling for business insights, we often very much rely on the SQL query to do data analysis and analytics. We can achieve the same through some BI tools as well. But if we are comfortable with SQL then I am sure that you will prefer to write quick query rather than designing something in tool. This post will demonstrate some awk commands equivalent to SQL statements.
The only requirement if you want to use SQL is, you need database with SQL capability. Again, if you have data, still most of the environment has database so it should not be a problem. So open SQL editor and write query, you are done !!
But imagine that the data you are working with, is not in database. It might be in flat file. In real world, I have seen most of the data transfer happens through flat file. Direct database connection to production server from external system is not recommended for enterprise system. Hence, FILE is the solution for transmission.
In any enterprise data warehouse (EDW) system, standard workflow for the entire ETL process is like below:
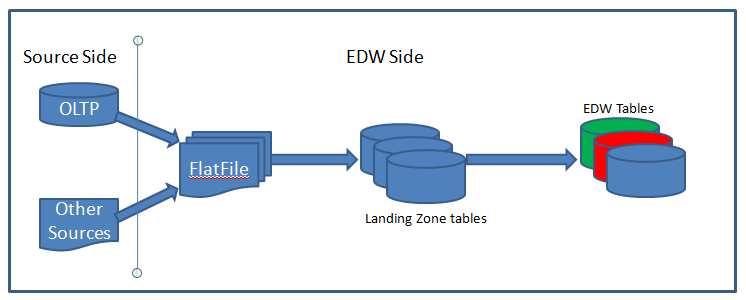
Once the data is in the database, you can apply SQL. But, what if you need to analyse data before loading into table?
Or in general you have any flat file anywhere. Your requirement is to analyse data (eg. doing some analytical query like sum/group by/count) or filtering data based on some condition.
Or you are working in Big data environment (modern trend). Before loading into hadoop ecosystem (hdfs), you want some manipulation or analysis.
You can do almost anything you want, YES, almost anything as you can do in SQL in database table, on the flat file using awk in unix/linux. Only assumption is the file is in text format and delimited. If not, converting is not very big deal though.
So let’s get started how to dig into flat files using awk in unix/linux. Read On Page 2..
Great content. This help alot. Thank you so much.
No problem. Thanks to you too for going through the content.
What a great content 🙂
Thanks
Thanks Jessica !! It means a lot. 🙂
The problem is that awk is NOT a CSV parser.
I.e. with the , separator, if we have a field value of “SURNAME,NAME” in this case the AWK threats it as two different fields.
Use goawk instead.
Yes. Good point. If the delimiter is part of the column value itself, then awk will fail to operate. We always encourage to use character like pipe or something else as delimiter which doesn’t present in the data. GoAWK is good solution for this. But yet to available as part of distributions.